
酷玩实验室作品
首发于微信号 酷玩实验室
微信ID:coollabs
不久前,一家叫做“摩尔线程”的厂商宣布自家的第一款游戏显卡MTTS80在双11开启限量销售。
不同于独霸业界的英伟达和AMD,摩尔线程是一家新杀出的国产GPU厂商,光从性能参数标上来看,MTTS80甚至能够跟RTX30系显卡掰掰手腕。
难道国产显卡真的要从此崛起了吗?

但很快,就有热心网友扒出了一些技术相关的细节:
摩尔线程可能直接购买了一家叫做Imagination的芯片IP厂商的技术授权,在此基础上来做自己的GPU,自研程度并不高。另一个佐证是这款显卡的驱动只有DX9,能够支持的游戏寥寥无几,还都是将近10年前的老游戏,而现在主流游戏都已经达到DX11甚至DX12。
这就有点像武侠小说里那种外功很强、但内功很弱的偏科选手,一旦遇到内外兼修的高手,只有被吊打的命。
更魔幻的还在后面,虽然在电商平台开启了预售,但这个预售是限量的,还得去摩尔线程的官媒填表申请一个叫做必购码的东西才能下单。

结果显卡上架了,好多人的必购码还没有着落,也不知道官方限量是多少,难度堪比春运火车票。
更让人哭笑不得的是,官方售价2999,大家都觉得略贵,反应过来才发现在商品描述的灰色小字写着这显卡还是绑定一款主板售卖的。

截止到11月16号,还没有看到任何媒体发表这款显卡的实机评测。总之在一连串的迷之操作下,MTTS80发售了,但没完全发售,很难不让人怀疑这其中有什么猫腻。
经过一番搜索后,我发现了一些端倪。
摩尔线程这次发布会的重点是一款叫做“MT-春晓”的GPU芯片,MTT-S80显卡只是基于它设计的一款产品,而更重要的是一款通用GPU——MTTS3000。
它的受众并不是广大追求4K60帧、特效、光追拉满的游戏玩家,反而是那些门槛壁垒很高的AI和数据中心企业用户。
所以,作为官方口中的游戏显卡,MTTS80就处在了一个不尴不尬的地位,甚至连首发都搞得如此仓促,更像是先占个坑的行为艺术。
到底中国的游戏玩家什么时候能用上靠谱的国产显卡呢?现在的国产GPU厂商都在搞什么?中国的GPU芯片自研到底该怎么走呢?
大家好我是Hugo,今天我们来聊聊国产GPU的现在和未来。
01
我们一般所说的GPU,是指用来渲染游戏图像的显卡。
因为CPU要负责整个计算机系统的控制,就像一个博士,可以应对复杂的大问题,但面对彼此独立的大量简单计算,即大规模的并行计算,速度就不行了,反而是找一大群中学生比较好。
今天屏幕中的3D物体在电脑里都是由一个个三角形组成,需要对数以万计无规律的三角形坐标进行大量的并行计算来进行图形的变换和渲染,从而确定屏幕上每个像素点该怎么显示,所以光靠CPU根本无法让大型3D游戏流畅的运行。
3D游戏出现早期,电脑需要带一个图像加速卡,英伟达正是看到了机会,在图形加速卡的基础上,发展出了专注并行计算的GPU,内部拥有大量的计算单元,可以同时进行大量并行计算。
世界上第一款GPU是英伟达的GeForce256,可以说是划时代的产品,老黄和英伟达也从此坐稳了显卡界的第一把交椅,然后AMD也从惨烈的竞争中杀了出来,与英伟达二分天下。
随着显卡技术的发展,图形渲染逐步形成了一套处理流水线:用点构成面、几何变换、光栅化、像素着色……这套流程通常被叫做“渲染管线”。
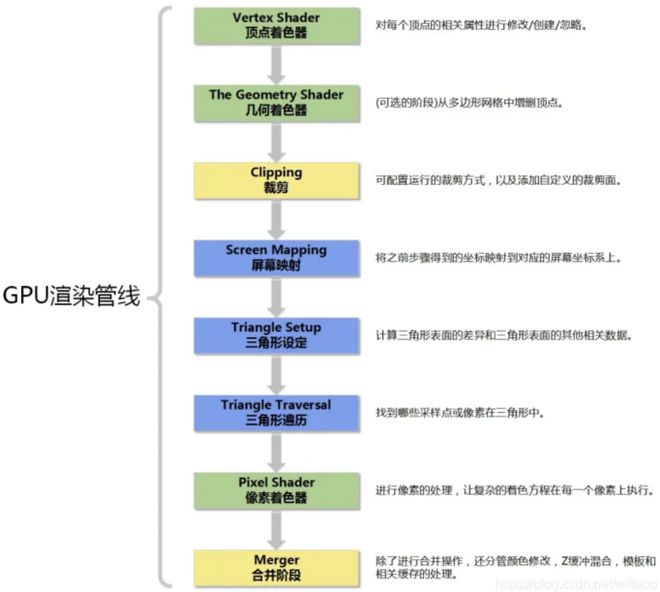
开发者们都想利用显卡完成更加酷炫的视觉效果,所以需要架构设计师开放管线内部分节点的权限,能够自主编程,英伟达引以为豪的CUDA核就是这个设计思路,把可以自主编程的节点放到通用的并行计算池来计算。
完成了这些架构后,GPU的格局就打开了。
因为除了游戏图形渲染,会用到大规模并行计算的领域还有很多,比如加密货币挖矿和目前已经渗透到各行各业AI计算,干这些并不需要用到“渲染管线”的其他功能,明显浪费了服务于游戏的GPU的能力。
所以为了进一步强化并行计算能力,各大厂商开始研发有一种非图形渲染的通用GPU(GPGPU),最好的还是英伟达和AMD。
比如英伟达的H100能达到每秒钟3.2亿亿次浮点数计算(3.2petaFLOPS FP8),毕竟本质还是并行计算,强者恒强。

图形渲染和通用并行计算也许总有一天会整合到一起,但目前来说还属于两个赛道。
对于国内来说,这几年数据中心、AI、自动驾驶等应用越来越火热,国内厂商的积累和精力投入有限,先把被英伟达和AMD统治的游戏显卡放在次要位置,更多都扑在通用GPU上。
图形渲染显卡优先满足的是汽车、飞机、工厂这些对渲染性能要求不那么高,但应用更广泛的领域。相比之下,高性能游戏显卡的需求是靠后的。
有了早年间被美国芯片技术封锁的教训,国内的GPU研发和量产工作已经有一段时间了。
果不其然,就在今年10月,美国再一次升级了对中国的芯片管制,禁售高性能的通用GPU,台积电这种生产代工厂也同样受到约束。
虽然对美国这种变本加厉的行为有预判,但还是有一些国内厂商中招了。
一家叫做壁仞科技的7nm通用GPU原本已经准备在台积电量产了,但因为参数中的传输速率刚好超过了新规中600GB/s的阈值,生产被直接叫停。壁仞科技不得不主动降低性能,直到现在也没有恢复生产。

前景未知导致公司在这个月计划裁员三分之一,是对国产GPU的一次严重打击。
这次的芯片管制升级,美国意图很明显,为的就是打击国内的AI发展。
10月份,正是AI绘画让专业画师和吃瓜群众都直呼“卧槽”的时间啊!上一次的芯片法案直逼我国的芯片生产,这一次更是封锁了AI发展的上限。那下一步呢,有没有可能连玩家们视若珍宝的游戏显卡也遭殃呢?
其实这个可能性并不低,无论是图形渲染显卡还是通用GPU,都在未来有着不可限量的广阔应用,甚至关乎到国家信息化水平和国防安全。
我们可以做个畅想,假如在10年后,元宇宙的虚拟世界初见规模,成为大家工作、生活、娱乐的基础建设,单眼16K、120Hz刷新率的VR头显变成了我们和虚拟世界交互的媒介,AI构筑了大量的虚拟内容并担当起了交互NPC的角色。
要支撑起这么庞大的虚拟世界的外在和内在,图形渲染和AI训练推理都是不可或缺的。到那时,图形渲染显卡将会变得和CPU、通用GPU一样重要。面对这种主导了一个时代的大机遇,美利坚会怎么做,想必不用我说了吧。
就算10年后的未来不是元宇宙,但新技术的发展肯定也是离不开GPU的啊。到了那时候,我们可能还在用着落后了两三个世代的芯片,再一次被踹下了世代的列车,最后被对方高一个等级的AI算力在各领域吊打。
所以,无论是高性能的GPU,还是CPU、NPU,自主设计和量产都是我们必须要渡的劫,上刀山火海都在所不惜的那种。
02
芯片制造中,高精度制程特别是EUV光刻机这些老大难问题已经人尽皆知了。
但芯片的设计,尤其是高性能芯片的设计,难度也不输于高精制程,而且CPU和GPU的架构完全不一样,CPU设计得很溜,并不代表GPU也能如法炮制。
比如苹果和英特尔,都在GPU研发这块吃过瘪。苹果我们一会儿再说,英特尔在桌面电脑CPU领域可以说是一哥的存在,但自家的Arc显卡就没那么顺利了,性能上拼不过A卡和N卡的同期产品不说,显卡驱动上也是问题频出,到现在还是bug不断。是不是也有点摩尔线程那味儿了?

经过30多年的发展,芯片领域分工明确,能设计芯片不代表能生产芯片,反过来也一样。甚至就连设计本身也被细分成不同的工作,能够设计生产两手抓的公司非常少。就算是设计也被细分成了多个领域,比如EDA、IP、芯片设计等等。
隔行如隔山了属于是。
EDA是指电子设计自动化软件,来完成超大规模集成电路(VLSI)芯片的功能设计、综合、验证、排版、布线等工作,有点类似于芯片设计界的Photoshop和3DMax。
芯片的本质是晶体管开关组成的逻辑电路,比如两个输入都是1才输出1的“与门”,两个输入都是0才输出0的“或门”,输入与输出相反的“非门”。这些简单的逻辑运算经过的排列组合,才让芯片拥有了算力和功能。但芯片中的晶体管数以亿计,这么复杂的结构,全靠工程师手搓是不现实的。
如果把芯片设计比作烹饪,那EDA相当于厨房的灶台,不然我们就只能钻木取火了。
为了进一步提高设计效率,工程师们还设计出了能够重复利用的小型模块,也就是IP核,和我们平时说的IP有异曲同工的地方。一些实现特定够功能的部分就可以用现成的IP核来实现。
所以,芯片设计厂商在研发新型号的时候,会先向IP厂商购买自己需要的IP核,不用一切从零开始,摩尔制程就是这么干的。
IP核授权也有不同的层级,比如软核只提供代码,固核提供门电路层面的社交和验证,硬核提供物理层面的布局布线甚至仿真验证,拿到代工厂可以直接生产。越往上,系统越稳定,开发难度越小,但可扩展性越来越低。
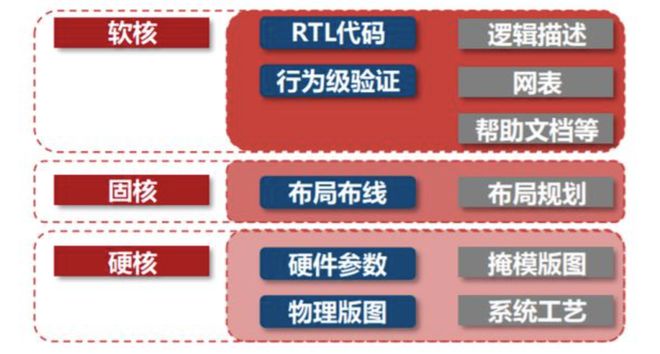
IP就好比是烹饪的食材供应商,不然想做饭我们还要自己种菜。而且这个供应商还贴心地提供不同加工度的食材,你可以买到一整块牛肉(软核)自己切块切条再调味,也可以买到切好的牛肉块或牛肋条(固核),甚至还能买到带调料、腌制好的秘制牛肋条(硬核),自己下锅炒一炒就能吃了。
当然,买了预制的牛肉肋条,你也就不可能做出整块的牛排了,但对厨艺要求很低。
有了灶台和食材,至于做出的是黑暗料理还是满汉全席,就看厨师手头的厨具和厨艺了,这也就是芯片的具体设计了。
这是一套系统工程,从最开始的市场需求分析、架构设计、性能、功耗的评估,软硬件功能的代码级实现,仿真验证,再到偏生产端布局布线的物理设计和验证,代工厂制作样片和测试样片,产品的亮相和宣发,最后才是量产阶段。
每个环节就好比做菜过程中的每个步骤,食材的处理、刀工、厨具选择、火候掌握、调味、雕花、装盘,哪怕是同一个菜谱,不同水平的厨师做出的味道可能也截然不同。
江湖上都称英伟达的黄仁勋为“皮衣刀客”,说他“刀法好”,能够精准拿捏每款显卡性能上的差异,满足不同消费能力的玩家,就像是优秀的厨师能够精准把控每一位客人的口味一样。

EDA、IP、芯片设计的三足鼎立,不同的厂商各主一方。
ARM几乎垄断了移动端CPU的设计,AMD和英伟达在GPU上有绝对的统治力,Synopsys和Candence则EDA、IP两手抓,英伟达就会购买前者的IP授权。
EDA、IP、设计、生产也是相辅相成、共同进步的。
EDA能过帮助工程师们提高设计效率,设计的反馈也能够帮助EDA更好地优化和更新软件。从芯片产业生态形成初期,这几个领域就从简到繁,不断积累经验和技术才形成了美国如今的芯片垄断地位,缺了哪一块都玩不转。
比如前面提到苹果的例子,和PC机不同的是,手机的芯片更多采用的是一种SoC(SyestemonChip)设计思路,就是把CPU、GPU、NPU这些芯片全部集成到一个封装里,在2017年之前,iPhone上的GPU是购买的是英国公司Imagination的IP授权,就是视频开头疑似授权给摩尔线程的那个厂商。

很多国内GPU厂商,也都是先购买了Imagination的IP授权,开启自研之路,也埋下不确定因素。
03
但正如一开始提到的,购买现成IP的自研含金量到底有多高呢?这要看国内厂商买的是原材料还是加工好的“预制菜”了。
一方面,通过软核授权来开发高自研度的难度非常大,除了硬件,还要重新编写配套的软件,后者在国内是很稀缺的,以至于目前发售的国产图形渲染显卡的优化水平都非常不乐观。
像摩尔线程这种成立不到两年就拿出来卖的,大概率更偏向预制菜,味道可想而知。想要在这个基础上搞出自己独到的东西,也要看IP厂商能够给予多大的技术支持。
就拿Imagination来说,它是第一个在移动端GPU上实现实时光线追踪的厂商,很善于在性能和功耗之间做权衡,在IP厂商也是排得上号的。

如果说在桌面PC领域的芯片三巨头是英伟达、英特尔、AMD,那移动领域的芯片三巨头非ARM、高通、Imagination莫属。
但苹果一直有一颗自研GPU的心,于是悄咪咪地挖了Imagination不少的工程师过来,并于2017年宣布终止与Imagination的合作,还要在2年内搞出自己的GPU。
这次跳反着实把Imagination坑惨了,因为在当时它和苹果已经合作了十年,一半以上的营收都来自苹果,深度绑定,合约终止、人才流失后市值大降。
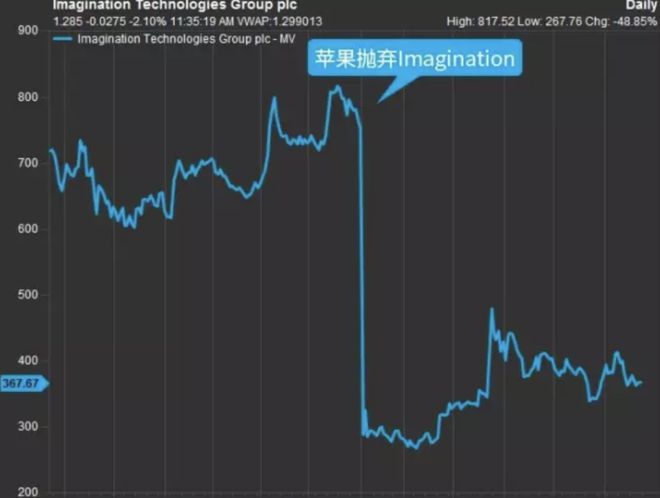
这时,中资公司凯桥资本化身白衣骑士出资收购,救Imagination于水火之中,并通过一番操作绕过了美国的监管,指望其能弥补国产GPU行业发展短板,这才有后来Imagination对国内厂商的全面支持。
但后来情况的变化就远远超出了芯片行业本身的市场逻辑。
2020年4月,原本有4名中国董事进入Imagination的董事会,但这个计划却被英国政府出面干预了,表示公司仍然隶属英国,想要公司主导权门都没有。还有高官辞职表示“不愿成为被中国政府控制的公司的一份子,此举会损害到公司在美国的合作业务”。
这一年,Imagination在中国市场的营收仅为总营收的10%,实在留不住人家。
更让人觉得离谱的是,就在被苹果抛弃3年后,Imagination又重新和苹果签订了IP授权协议。

这就好比女主被高富帅渣男抛弃,走投无路之际被中资白骑士收留。但这女主非但不知恩图报,反而对中国这边的白骑士吆五喝六,这也不行那也不行,反过来对渣男唯唯诺诺,更可气的是最后还重修旧好。
这个白骑士当的可以说是相当窝囊。
而当本来利益纠葛就错综复杂的商业博弈,再加入国家意志的政治角力,这波收购对于国产GPU发展到底有没有帮助,是要打个问号的。
更让人担忧的是,如果大部分国内厂商都在购买没什么自主研发空间的“预制菜”IP,不仅对技术发展无益,更有可能导致国内厂商内卷,急功近利,为了抢占市场研发出一些根本没有实际价值的GPU产品。
从已发售国产GPU的表现来看,虽然通用GPU普通人接触不到,但从消费级显卡来看,绝大部分产品实际上并没有达到用户们的预期,但出于抢占国内市场或者其他商业和资本的考量,又不得不把不成熟的产品拿出来卖。
怎么说呢,虽然拿来主义害死人,但面对越发紧缩的芯片市场,也只能说是厂商的无奈之举。
毕竟,连坐拥漂亮国30多年芯片产业积淀的苹果和英特尔都对GPU自研感到如此棘手,而现在的国产GPU,就像是个没有师父带就被硬推入后厨的菜鸟,凭借着东拼西凑的菜谱,没法乱改也不敢乱改,只能用老旧的厨具和少得可怜的食材,小心翼翼地积累经验,还要时不时被坑。但不管怎么说,这个简陋的厨房算是搭起来了。
再怎么说,有总比没有好。
在这条GPU研发的道路上,国内厂商注定要经历一番磨难,走一些弯路的,但我相信未来肯定是光明的。
早年间,别说是CPU和显卡,我们就连内存、硬盘、主板都没法生产。但经过不断努力和尝试,现在这些设备都可以实现国产替代了,既然如此,从通用GPU开始,再到图形渲染显卡,再到14nm、7nm、5nm甚至3nm芯片量产,也终会有摆脱美国制约的一天。
面包和牛奶都会有的,因为拼尽全力发展国产GPU的天时地利人和已经来了。
首先是美国科技脱钩和芯片禁令的加剧,国内产业必须放弃一切幻想准备战斗,此时此刻不是正大力发展芯片的最好时机么?此为“天时”。
国产GPU厂商目前的主要阵地还是面向AI和数据中心的通用GPU。随着AI和云计算的发展,需求量在未来只多不少,再加上一些28nm的芯片订单拉来“贴补家用”,国产GPU厂商的生活也会越来越好。此为“地利”。
现在钻研国产GPU的主力军,并不是只有一腔热血的门外汉,它们的主要创始人大部分都在英伟达或者AMD这样的一线大厂有过相当出色的履历,一些甚至还曾担当要职,打下了良好的底子。此为“人和”。
海到无边天作岸,山登绝顶我为峰!
于逆境之中绝处求生,国产显卡和国产游戏命运其实非常相似,也唇齿相依。
国产游戏早年间在盗版、舆论和政策的多重因素下几近毁灭。但也硬是靠着一批批不堪向命运屈服的游戏创作者们左支右挡,凭借自己不断磨练的技术和坚定的意志,硬是在世界上立住了脚。在这个过程中,无数有情怀的厂商和游戏创作者化作了世代的眼泪,但后来者以此为阶梯,也成就了今天的国产游戏。
《古剑奇谭3》《永劫无间》《戴森球计划》《原神》……原来越多的国产游戏被全世界的玩家所知,甚至还能成为文化输出的有利阵地。在未来甚至还有和国外3A大作刚正面的《黑神话:悟空》。我不敢说国产游戏从此崛起了,但至少我们已经走上了属于自己的道路。

而这也许,也是国产芯片终将走上的道路。只是这条道路也许会更加漫长、更加曲折,但我相信我们一定能、也必须义无反顾地走下去。
酷玩实验室整理编辑
首发于微信公众号:酷玩实验室(ID:coollabs)
如需转载,请后台留言。

【相关文章】
★ 华为 Mate 50 Pro 拆解:主板预留 5G 射频芯片位置
★ 搭载自研芯片V2 iQOO 11系列发布 售价3799元起
★ 《女神异闻录5皇家版》PC需求:最低650Ti空间45G
★ 36氪独家|前蔚来副总裁创业做芯片,获小米领投5000万美元融资
本文地址:https://www.qubaike.com/hotnews/gewqsbpn.html
声明:本文信息为网友自行发布旨在分享与大家阅读学习,文中的观点和立场与本站无关,如对文中内容有异议请联系处理。







