

最近,差评君听到了一个好消息。
AI 算力领域的“ 图灵奖 ”—— MLPerf 测试,发布了一个关于当前主流 ai 芯片的基准性能的测试结果。
一家首次参加测试的芯片企业——墨芯人工智能,化身“ 草根英雄 ”,火速制裁了 AI 芯片的霸主英伟达。

墨芯 S30 芯片在主流 AI 模型之一的图像分类( ResNet50 )中,以 95784 FPS 的单卡算力夺得全球第一。
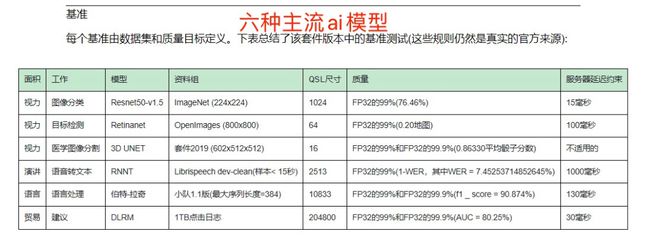
是英伟达现役最强 GPU——A100 的 2 倍,是即将上市的英伟达 H100 的 1.2 倍。

对芯片不太了解的差友,可能不太了解这事的重要性。
市场研究公司 Omdia 调查显示:英伟达占据了全球人工智能( AI )处理器 80.6% 的市场份额。
而作为他的旗舰产品 A100、H100 几乎代表了全球同类芯片的最高水平。
如果墨芯 s30 真能超越英伟达最新科技的话,说不定双方的团队已经在洽谈收购的事情了。
不过,更逆天的是,墨芯 S30 竟然用 14nm 纳米的制程就暴打了 4nm 工艺的英伟达最强 GPU——h100 系列。
这是真的 6 翻了。
虽然,每一年都有一两家企业叫嚣着:拳打英伟达、脚踩英特尔。

但是能用 14nm 工艺超越 4nm 工艺的芯片公司,英特尔看了都要馋。

所以要是不出意外的话,凭借这个技术,名不经传的墨芯公司完全可以,名扬大中华,技术封锁美利坚,然后带着欧盟 27 个小弟称霸世界了。
好了,说到这里,想必各位差友都知道了
如果不出意外的话,那么意外就来了。
很快有人扒出来:墨芯这瓜,它不保熟。
虽然,这个叫做 MLPerf 的性能测试,权威且保真。
但是,也有很多周旋的空间。

比如,虽然墨芯公司官方的宣传里,着重强调了“ 算力全球第一 ”。
但后续有人扒出了,这个“ 全球第一 ”的数据经过了“ 美化 ”的处理。

关键性的分组标签,被人p掉了。

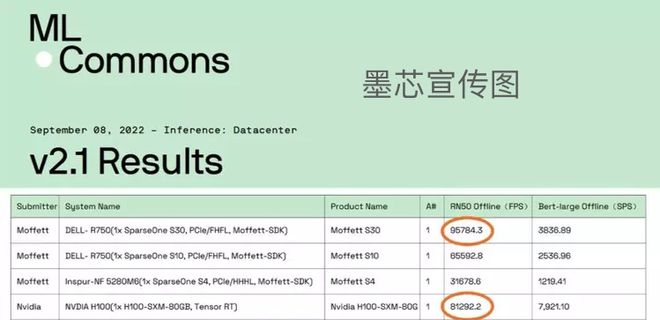
原来,这个 MLPerf 测试它是分为 Closed( 固定任务 )和 Open( 开放优化 )两组。

Closed 代表的固定任务分组,进行的是正式比赛。
也就是说,厂商们,需要运行统一的算法,对同一个模型图像分类( ResNet50 )进行计算,实现芯片之间的性能比较。
而这个 open 分组就是用来展示一些创新性的成果的,也就是所谓的表演赛。
在这个组别里,只要不改变测试的内容,你想怎么玩都行。
而墨芯参加的恰恰就是 open 分区的测试。
于是,墨芯 s30 凭借着“ 稀疏化 ”的算法,用“ 无规则格斗 ”的打法胜了英伟达的“ 空手道 ”。
然后,公司再一运作,删删减减,一个全球算力第一的营销广告就这么华丽的出现。

又一个营销鬼才。
不过这岂不是证明了墨芯用的稀疏算法,能大幅增加 ai 芯片的算力?
情况也确实是这样的。
所谓的稀疏算法,又称剪枝。
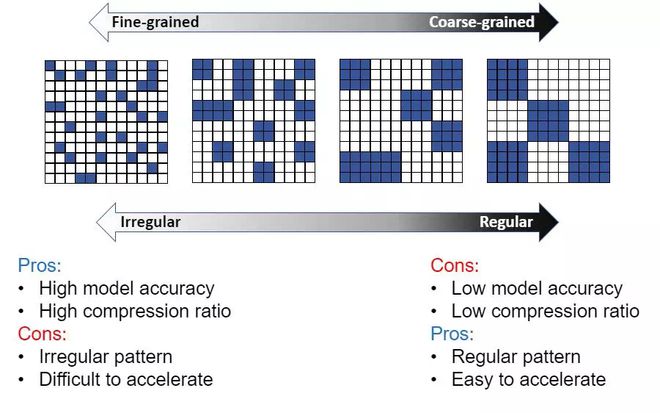
就是在 ai 模型的训练过程中,把一些不重要的运算过程去掉,大大增加计算的效率。
这就像识别一个超清的图像,如果我们降低到标清的水平,传输速度就会快上许多。
但是,这种成倍提升算力的“ 黑魔法 ”怎么会没有代价呢?
一来, 这种提升算力的方式应用场景比较小,不适合高精度的模型训练。
二来,算力是通用的,ai 的模型并不是,这就需要根据不同的模型,研究不同的稀疏算法。
但问题的重点在于,稀疏算法并不是墨芯一家的专利,英伟达家的 h100 也能支持。
而且,英伟达依然是目前唯一一家在每轮 MLPerf 基准测试都参与所有主流算法测试,然后横扫各项测试成绩的全能选手。
所以说,回到 ai 芯片的性能本身,我们还是很难否认英伟达在这方面的统治力。
不过,抛开这次的“ 吊打英伟达 ”的乌龙事件不谈,最近几年国内还是涌现出一批优秀的国产 ai 芯片。
比如在今年 3 月,壁仞科技诞生了一枚名为 BR100 的芯片。
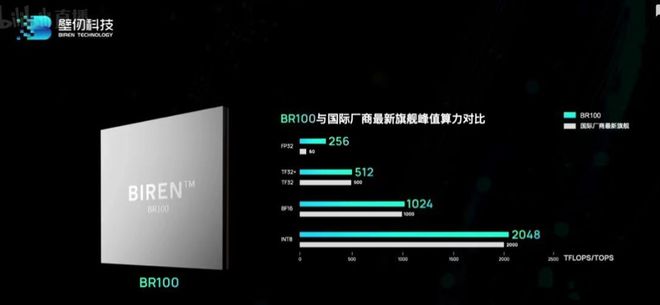
这颗芯片 16 位浮点算力在 1000T 以上,8 位定点算力达到了 2000T 以上,打破了此前一直由国际巨头保持的通用 GPU 全球算力纪录。
而 19 年,华为发布的昇腾 910 芯片的算力也号称是当时国际顶尖水平的两倍。

看来,真金白银地砸进去还是有水花的。
不过,当国内芯片的性能开始触碰到全球算力的天花板的时,我们才发现差距不止在算力上。
国内的一大批创业者们,早已经在追赶英伟达的过程中,撞上了第二堵南墙:生态。

2016 年前后,ai 的浪潮席卷中国,人人都想做“ 中国的英伟达 ”。
但后来,国内的厂商们慢慢发现AI芯片陷入了一个困境:ai 芯片无法成为一个单独的产品。
探境科技的CEO概括了这种复杂的处境:
英伟达的GPU在AI应用中很难被替换,因为英伟达的GPU除了能处理AI的工作,还能进行图形计算等。
即便AI专用芯片性能大幅提升,也不能满足最终应用的所有需求,客户还要再购买GPU。
以至于,大家都以兼容英伟达的软件开发系统目标,如果不兼容,代码重新开发或者移植的成本太大了。
之所以会有这样的问题,是因为英伟达依靠在 gpu 上的先发优势建立了自己的生态--CUDA ,一套与英伟达芯片配套的软硬件开发的工具包。

能为几乎所有主流的 ai 模型服务,同时大量的开发者也在反哺和完善这个生态。
据 2021 年英伟达官方最新数据显示,英伟达生态的开发者数量已接近 300 万, CUDA 在过去 15 年总计下载量达 3000 万次,过去一年下载量达到 700 万。
这就好比同样是一个野外求生俱乐部。
国内还停留在,拿着一本野外求生指南让客户自己学的阶段时。
而英伟达,已经提供了全套装备。

甚至送来了一个贝爷。

这就导致了,AI的软件生态成了英伟达生态。
而英伟达的软件生态,尤其是 CUDA 相关的核心部分都是闭源、封闭的。

在这样的封锁下,想要将自家的软件与英伟达的生态兼容的难度可想而知,建立一个新的 AI 生态更是痴人说梦。
一位国内AI芯片公司软件的负责人直言:“ CEO 和 CTO 都听不懂我的工作。一些国内 AI 公司创始人对软件的认知,相比领先的国际大公司,我认为有十几年的差距。”
英伟达 GPU 强大的产品力加上顶尖的 CUDA 软件生态,使得它在AI领域的势力不可动摇。
包括微软、三星、 Snap 等在内的 25000 多家企业客户,都接入了英伟达的 ai 推理平台。
而且它比想象的要难以超越。
因为他不仅比你更强,还比你更努力。
在过去的十年中,英伟达在研发方面的支出持续扩大,根据财报,2021 年英伟达研发投入达到 39.24 亿美元。

所以,在这种全面的领先下,我们很难相信有什么公司可以在ai芯片领域,一步跨越大山一样的英伟达。
这一点,每年砸出去上百亿的英特尔深有体会。

而相对于全球其他的竞争者们,我们还面临着芯片制程的问题。
但即便如此,差评君觉得,差距越大,我们更应该脚踏实地地发展。
不要幻想一日赶英超美,而是紧紧跟在对手的身后,就像一头猎豹,等待敌人犯错。

【相关文章】
★ 英特尔旗下Mobileye:与吉利控股集团进一步扩大业务合作
本文地址:https://www.qubaike.com/hotnews/0eworn8y.html
声明:本文信息为网友自行发布旨在分享与大家阅读学习,文中的观点和立场与本站无关,如对文中内容有异议请联系处理。







